Foursquare Tips + Restaurant Grades Data Science Final Project
What if...
we knew which restaurants needed a health inspection based off of the words used in user reviews?
Motivation

Based off of the New York City Department of Health and Mental Hygiene (NYCDOHMH) and its restaurant inspection information, there are roughly 24,000 restaurants in the city. That's a lot of ground to cover if you're a restaurant sanitation inspector. So the purpose of this project is to see if Foursquare tips written by users can help identify and prioritize restaurants for review by the NYCDOHMH.
See the full source code and project work here.
Data Acquisition and Exploration
I acquired the restaurant grade data in CSV form through NYC Open Data. The CSV contained multiple inspection dates and code violations per restaurant, so the data was reduced to the latest inspection date per restaurant that had a grade value present. This produced a dataset in which each row was a unique restaurant with a letter grade ('A', 'B', 'C', 'Z', 'Pending', 'Not graded').
Using the address and restaruant name from the restaurant grade data, I queried Foursquare's API. If valid responses were returned, I then took the first result and queried the API again for detailed venue information. Foursquare rating, user check-in counts, price tier, and user tips were parsed from this API response. The rating, price, and check-in count were joined to the grade dataframe, while tips were stored in separate dataframe.
My initial approach to this project was to see if there was any correlation between a restaurant's grade and its numeric rating on Foursquare. Unpopular restaurants on Foursquare could be the result of poor sanitation habits was one of the original hypotheses. But after doing a rough plot of these two data points and observing basic computed values, such as mean, no immediate correlation was noticeable.
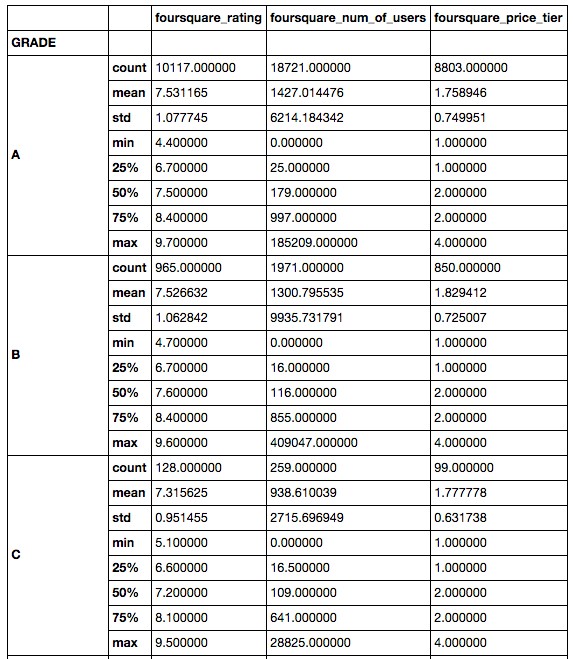
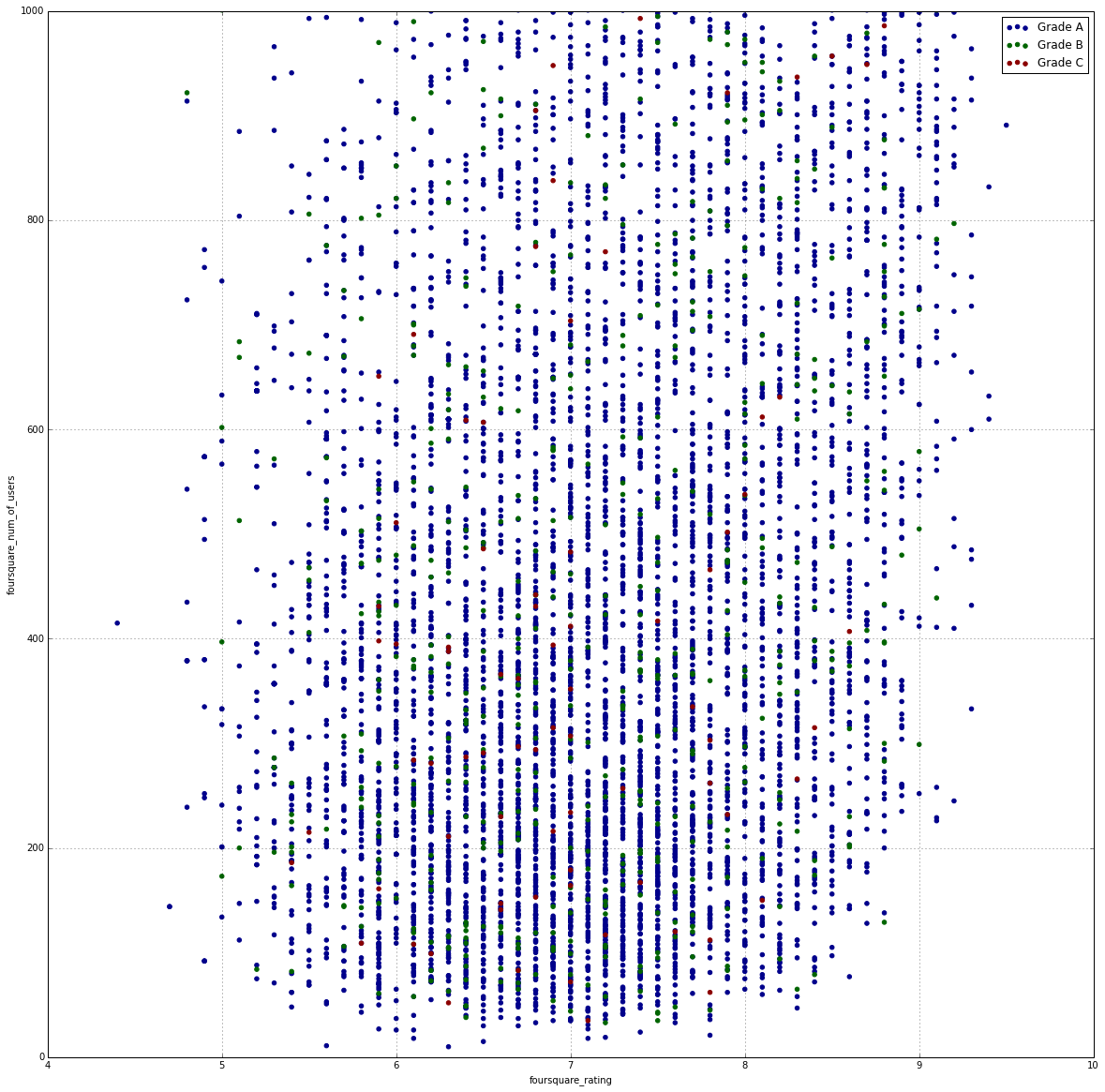
This caused the project to instead refocus on the textual tip data provided by Foursquare users. The tip dataframe was joined with the restaurant grade dataframe based on foursquare ID. Then each Foursquare tip in the dataframe was tokenized and broken up into parts of speech using NLTK. Adjectives were extracted from these word vectors and transformed into a sparse dummy matrix in which each feature was an adjective. An adjective is only included in the adjective dummy dataframe if it appears in more than 10 tips.
Analyses Performed
Check out the regression models in detail here.
Aside from evaluating the scores produced by different regression models when predicting a restaurant as grade "A" or grade "C", I also mapped out how a naive-bayes multinomial regression scores by NYC zipcode.
Conclusions
This is the weakest part of my project since AUC values indicate that any interpretation drawn from the data has a high probability of being the result of randomness. ¯\_(ツ)_/¯
Next Steps
- Double checking for words that appear for both grade "A" and grade "C" restaurants.
- The number of tips per restaurant is fairly low, so using more tips or refining the model to restaurants with a minimum number of tips might help. It could also be helpful to incorporate non-Foursquare data.
- Using Bigrams and Trigrams to measure the impact of word combos since sentiment analysis is weak when only used against individual words.
- Doing a deeper dive into certain areas of NYC instead of all restaurants in the city.